NVIDIA anunță integrarea NVIDIA NVLink, un sistem de interconectare de înaltă viteză, în viitoarele sale unități de procesare vizuală, ce permite partajarea de date între GPU și CPU cu o viteză de la 5 până la 12 ori mai mare decât în prezent. Acest pas va elimina una dintre cele mai importante limitări hardware din prezent și va facilita apariția unei noi generații de supercomputere ce vor avea o viteză de procesare de 50-100 de ori mai mare în comparație cu cele mai performante sisteme de astăzi.
NVIDIA va implementa tehnologia NVLink în arhitectura Pascal, succesoarea arhitecturii Maxwell și care va fi introdusă pe piață în anul 2016. Mai mult, noua soluție de interconectare a fost dezvoltată împreună cu IBM, companie ce va utiliza NVLink în următoarele generații de procesoare POWER.
“Tehnologia NVLink deblochează întregul potențial al unităților de procesare grafică prin îmbunătățirea transferului de date între CPU și GPU, minimizând timpul de așteptare al unității vizuale pentru procesarea datelor,” declară Brian Kelleher, vice președinte senior al GPU Engineering, NVIDIA.
“NVLink permite schimbul rapid de date GPU – CPU și îmbunătățește transferul de date efectuat în interiorul sistemului de calcul, astfel încât să elimine un obstacol cheie în cadrul procesării accelerate,” spune Bradley McCredie, vice președinte și IBM Fellow, IBM. ”NVLink le permite dezvoltatorilor să modifice mai ușor aplicaţiile de înaltă performanţă şi analiză de date, astfel încât acestea să utilizeze potenţialul sistemelor accelerate CPU – GPU. Credem că această tehnologie reprezintă o contribuţie semnificativă la ecosistemul nostru OpenPOWER.”

NVIDIA NVLink
Mulțumită integrării soluției NVLink în procesoarele IBM POWER și în unitățile de procesare vizuală NVIDIA Tesla, ecosistemul centrelor de date POWER va beneficia de întregul potențial de accelerare GPU în rularea diverselor aplicații, de la procese de calcul de înaltă performanță, până la analiză de date și inteligență artificială.
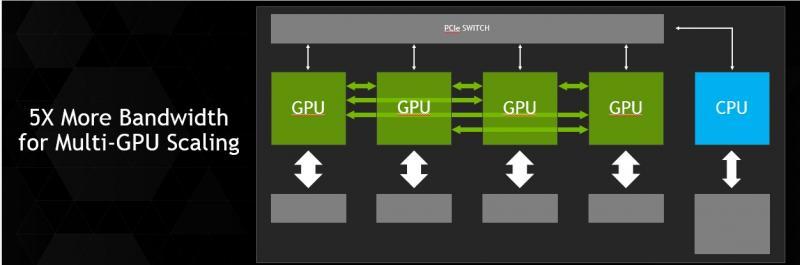
Avantaje faţă de PCI Express 3.0
Unităţile de procesare vizuală din prezent sunt conectate la procesoare bazate pe arhitectura x86 prin intermediul interfeţei PCI Express (PCIe), ce nu numai că limitează abilitatea GPU-ului de a accesa sistemul de memorie dedicat CPU-ului, dar are şi o viteză de 4-5 ori mai lentă decât sistemele de memorie CPU obişnuite. PCIe este un factor limitativ cu atât mai important în cazul conexiunilor dintre unităţile de procesare vizuală şi CPU-urile IBM POWER, ce dispun de o lăţime de bandă mai generoasă decât în cazul procesoarelor x86. Fiindcă NVLink va lucra cu lăţimea de bandă a sistemelor de memorie CPU tipice, sistemul îi va permite procesorului grafic să acceseze memoria procesorului central la potenţialul său maxim.
Această soluţie de interconectare cu bandă largă îmbunătăţeşte considerabil performanţele aplicaţiilor accelerate. Din cauza diferenţelor dintre sistemele de memorie – GPU-urile au memorii rapide dar de capacităţi reduse, iar CPU-urile dispun de memorii lente, de capacităţi mari – aplicaţiile accelerate transportă datele de pe mediul de stocare în memoria CPU, iar apoi copiază aceste date în memoria GPU pentru a fi procesate de acesta. Cu NVLink, transportul de date dintre CPU şi GPU se realizează la viteze mult mai mari, rezultând o viteză de lucru mult mai rapidă în cazul aplicaţiilor accelerate.
Memoria unificată
Viteza îmbunătăţită a transferului de date, împreună cu o altă caracteristică denumită Unified Memory (memorie unificată) vor simplifica programarea de aplicaţii accelerate GPU. Memoria unificată le permite dezvoltatorilor să trateze memoriile GPU şi CPU ca şi cum cele două ar fi un singur bloc de memorie. Astfel, programatorul poate lucra cu date fără a-şi face griji referitor la memoria pe care vor fi stocate.
Chiar dacă unităţile de procesare vizuală NVIDIA vor continua să funcţioneze prin PCIe, NVLink va fi utilizată pentru conectarea GPU-urilor la CPU-urile compatibile cu această tehnologie, dar şi pentru a oferi conexiuni de bandă largă între mai multe unităţi de procesare vizuală din acelaşi sistem. De asemenea, în pofida lăţimii de bandă generoase, NVLink are o eficienţă energetică per bit transferat superioară tehnologiei PCIe.
NVIDIA a proiectat un modul pentru găzduirea de GPU-uri bazate pe arhitectura Pascal ce au încorporată tehnologia NVLink. Acest nou modul GPU are doar o treime din dimensiunea plăcilor PCIe utilizate în prezent pentru GPU-uri. Conectorii din partea inferioară a modulului Pascal oferă posibilitatea conectării acestuia la placa de bază, îmbunătăţind design-ul sistemului şi integritatea semnalului.
Soluţia de interconectare de mare viteză NVLink va permite dezvoltarea de sisteme de o înaltă interdependenţă, o cale ce poate conduce spre supercalculatoare cu o mare eficienţă energetică ce rulează la 1,000 petaflops (1 x 1018 operaţii floating point pe secundă), adică mai rapide de 50-100 de ori faţă de cele mai performante sisteme ale momentului.